
8 MIN READ
Monday, February 26, 2024


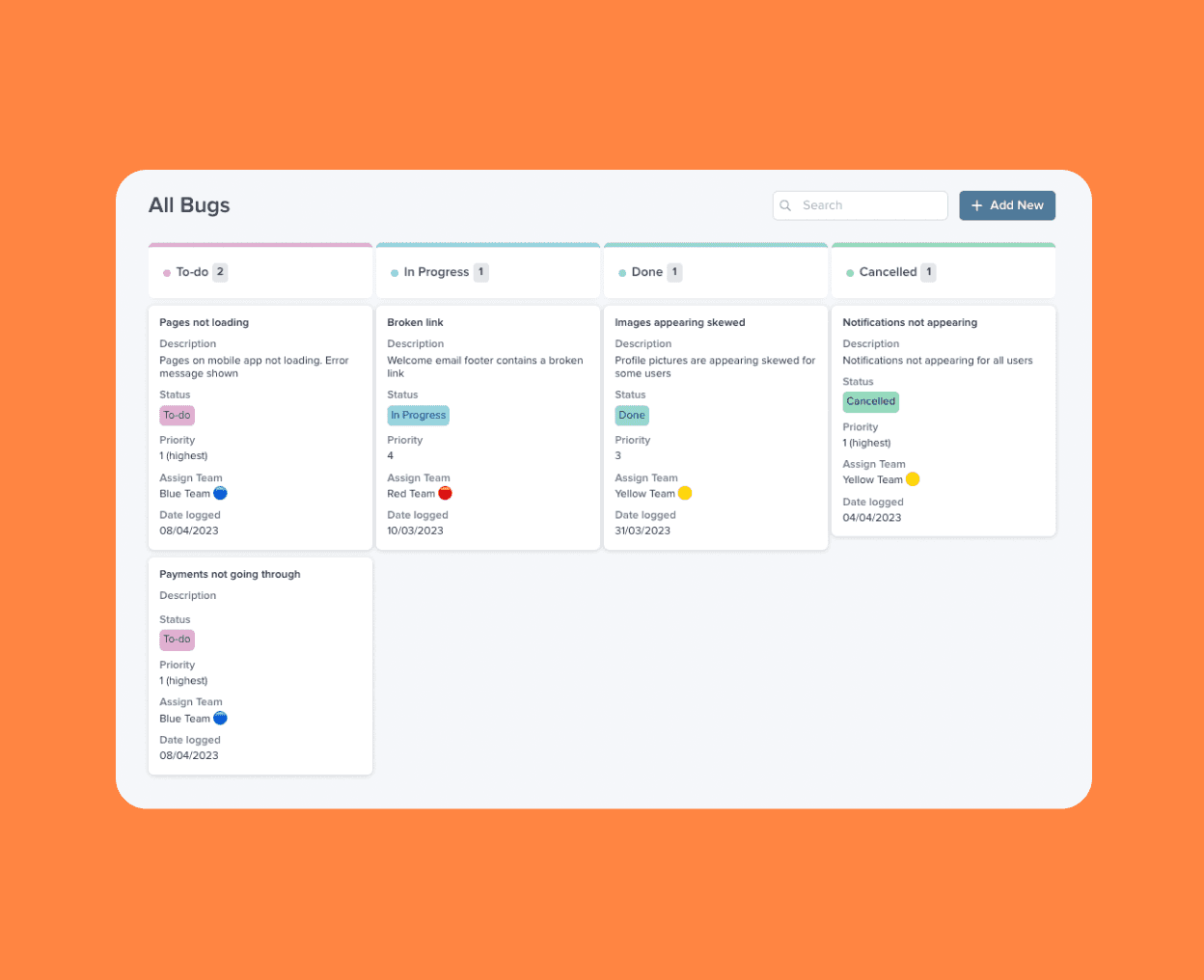
Plenty of businesses use Airtable to handle key processes like managing their team’s workflows, tracking product roadmaps, recording customer orders, and much more. But with Airtable, you can’t control what users can see or edit within your database. Everyone who has access to your Airtable has access to all the data in it. That limits what you can do with your data.
Some companies try to get around this by having more than one Airtable or bringing in other tools (like a Trello board or a Google Sheet or CRM software). The problem is now you're doing double work, as you need to update multiple sources of data.
Here’s a non-exhaustive list of what you can create with an Airtable app builder:
The good news is that you can use an Airtable app builder to create different types of web apps with your data.
A custom CRM
A portal where clients can check on their order
A project tracker
These serve as front ends for your data, where you can control what users can see and edit.
Plus, whatever changes you make to your data on the front end (like updating a customer order) are reflected on the back end (your Airtable), so you only have to update your data once.
Sign up for Stacker’s Free 30-Day Trial
With our no-code app, you can create web apps like product management trackers, internal workspaces, custom CRMs, and client portals without even writing one line of code. It allows you to create web apps where you can:
Control how the layout should look.
Decide how you want to share Airtable data with internal and external users.
To understand how Stacker’s features can help your businesses build apps from Airtable, start your free 30-day trial.


